Project Overview
This project explores the use of Reinforcement Learning (RL) to create intelligent gameplay strategies in an Auto Battler game environment. Using Stable Baselines3, Gymnasium, and the Deep Q-Network (DQN) algorithm, the AI learns to optimally place units on a board turn by turn.
Technologies and Frameworks Used





How the Game Works
Each player places a unit on the board each turn. After placement, the units automatically battle each other. The health points of surviving units are subtracted from the opponent’s total health. The game continues for 9 turns or until one player's health reaches zero. The player with the highest health at the end wins.
Reinforcement Learning Approach
The AI learns by interacting with a game mechanic that randomly places opponent units on the board. No human intervention is required — the AI gathers data independently through repeated gameplay. Each action (placing a unit) affects the evolving game state, and rewards are shaped based on combat outcomes and end-game results.
- Frameworks Used: Stable Baselines3, Gymnasium
- Algorithm: Deep Q-Network (DQN)
- Environment: The environment is represented as a discrete grid where each cell can either be empty, contain a friendly unit, or contain an opponent's unit. New opponent unit placement is randomized at the start of each turn to simulate a wide range of possible game states, encouraging the AI to develop generalized strategies rather than overfitting to specific patterns.
- Goal: Learn optimal strategies through reinforcement learning without explicit human feedback
AI Learning Cycle
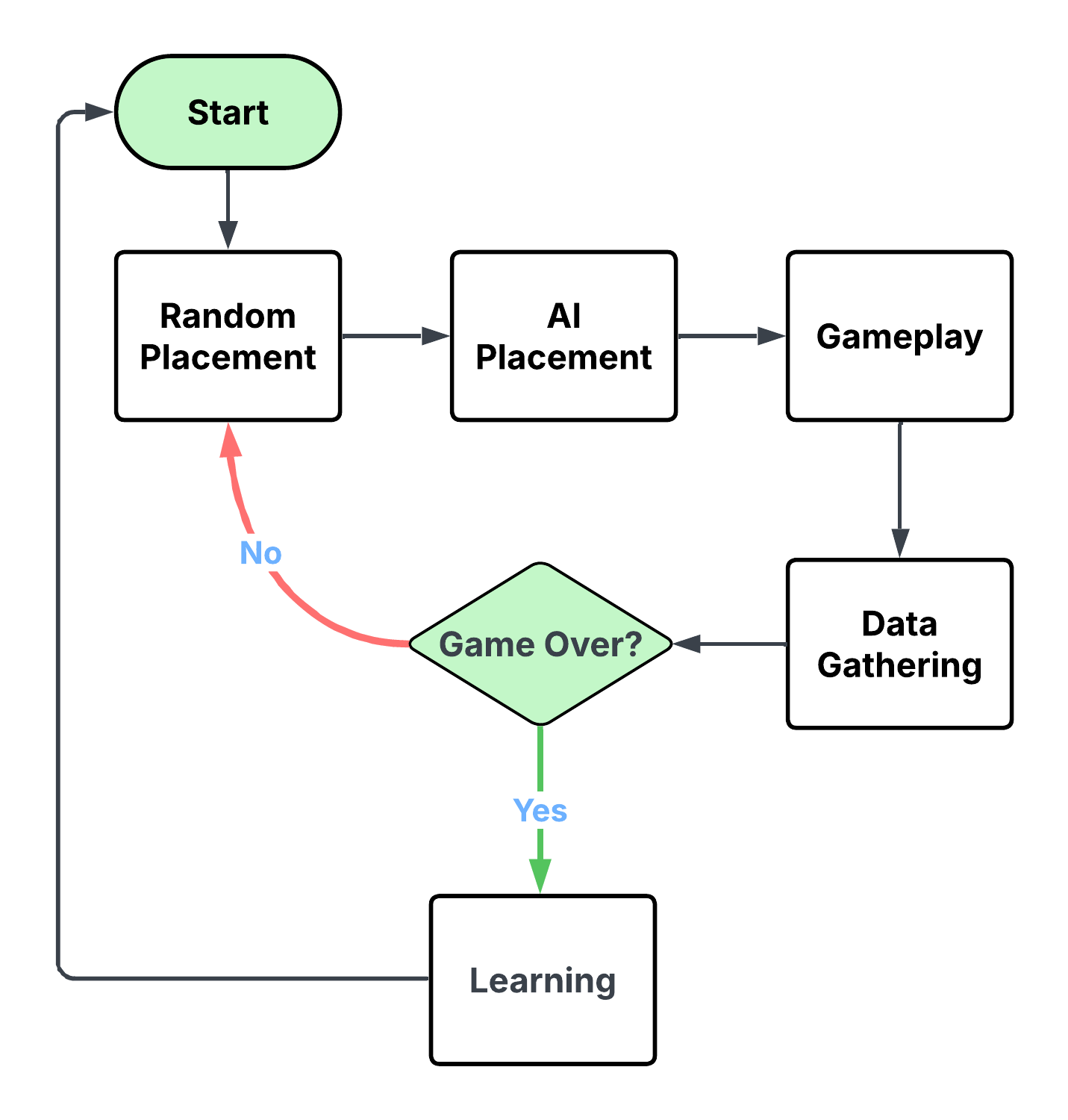
Figure 1: Flowchart showing the AI's training cycle in the Auto Battler environment, including gameplay, data gathering, and learning phases.
Current and Future Work
Work is ongoing to refine the AI's performance by improving the action space and reward functions. Teaching the AI to play against itself (self-play) is a key next step for deeper strategy development.
Additionally, I am exploring the implementation of an AlphaZero-style agent, using Monte Carlo Tree Search (MCTS) combined with reinforcement learning. This will allow for comparisons between different algorithms (DQN vs AlphaZero) to evaluate their effectiveness and learning speed in the Auto Battler environment.