04 · The platform

How it looks.
Real screenshots of the platform.
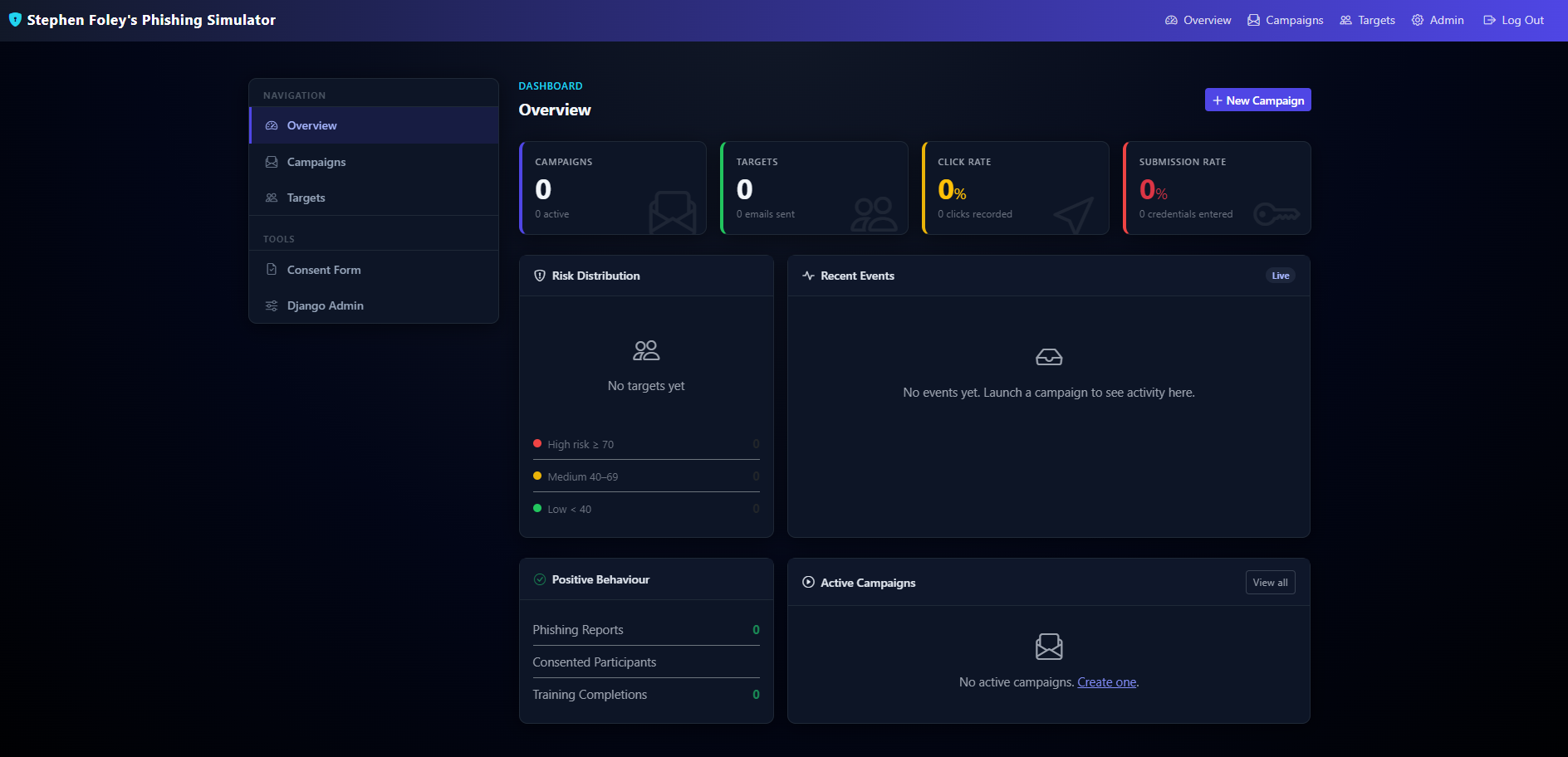
Dashboard — campaign funnels, risk distribution, live event feed.
Fake DocuSign landing page — cloned to match the real 2026 design, with federated Microsoft sign-in.
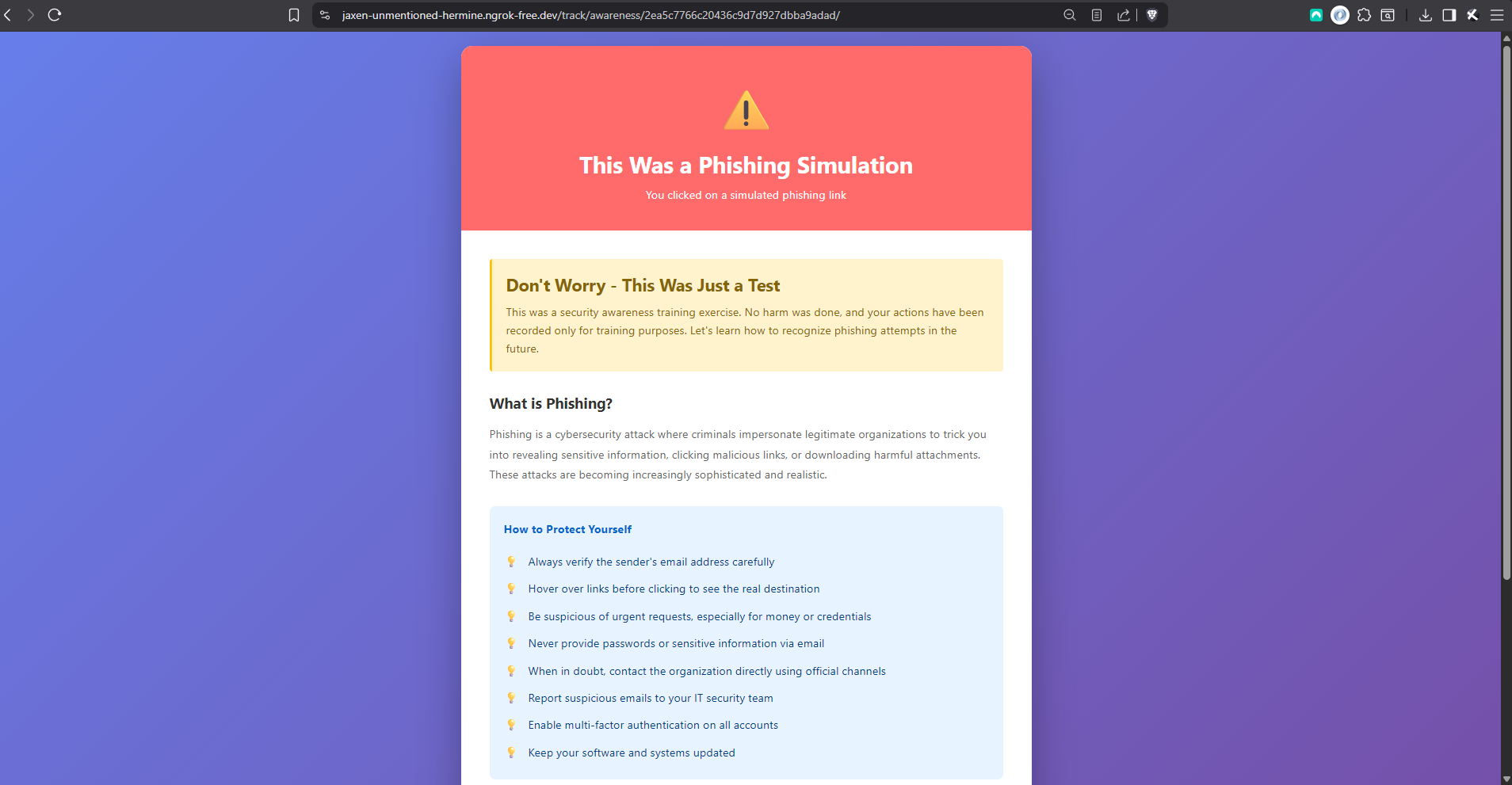
Post-submission training — scenario-specific red flags, shown immediately after any simulated credential submission.
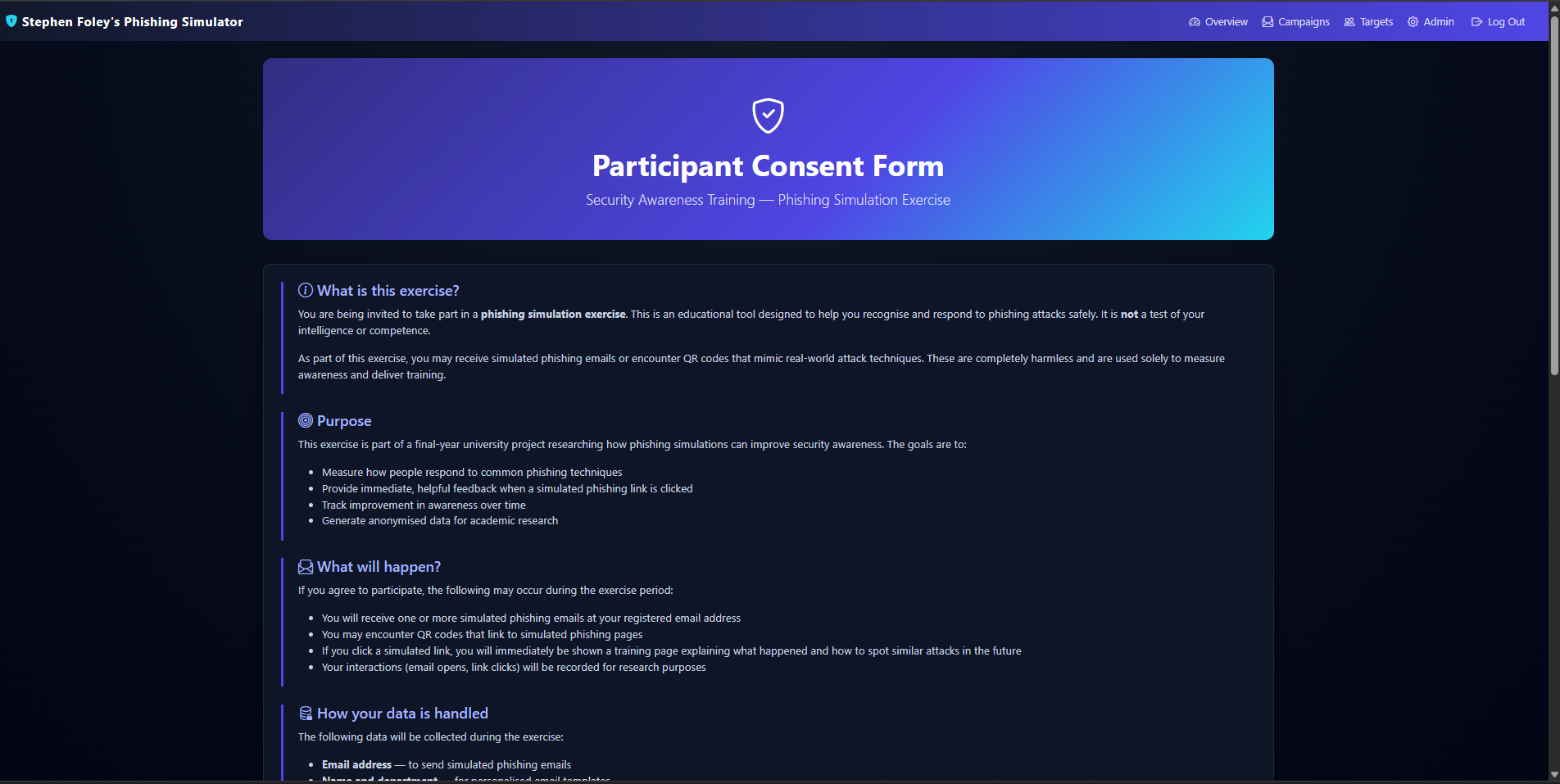
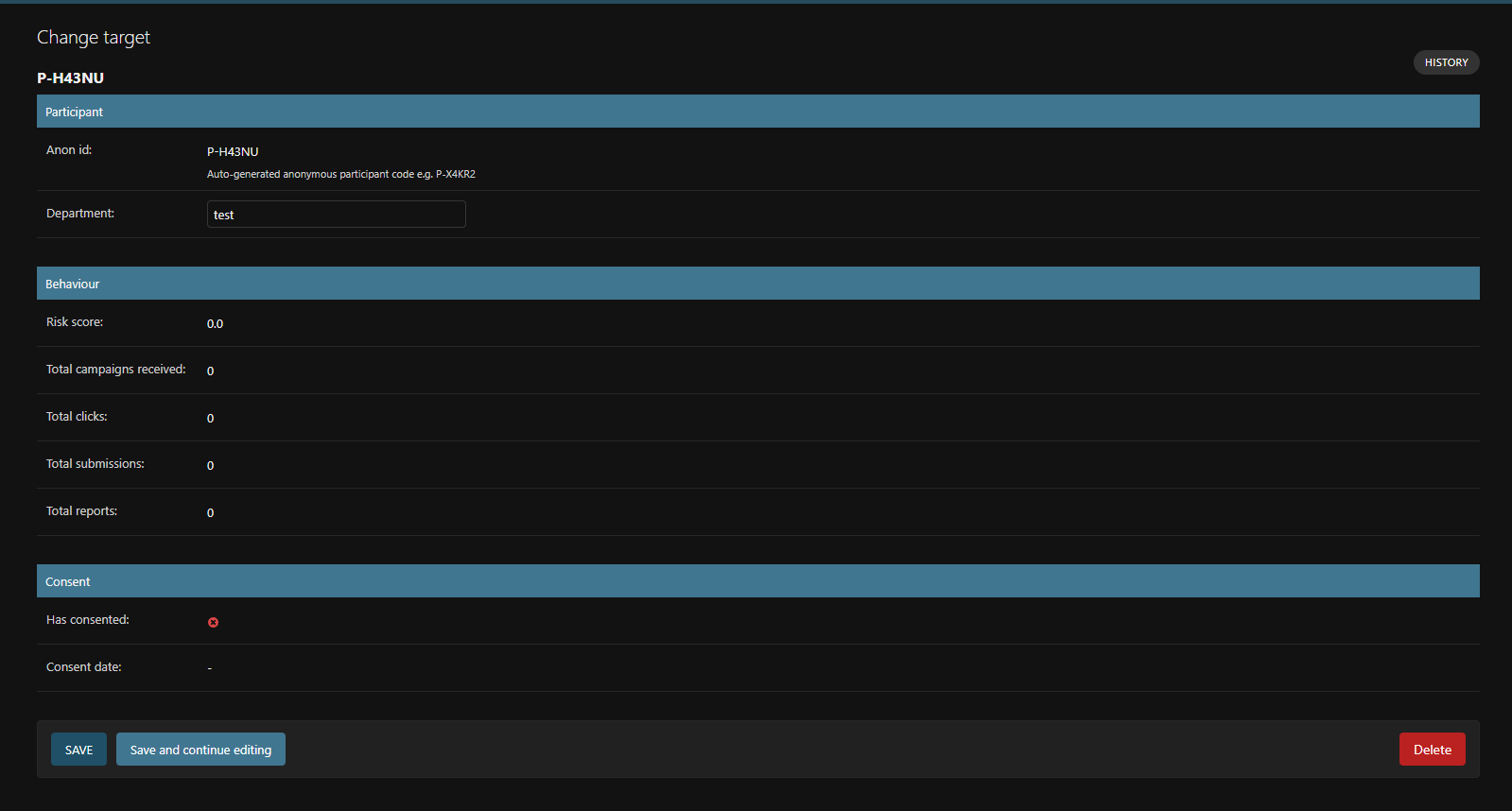
Informed consent flow — built into the tool, GDPR-aware, with a one-click withdrawal path.
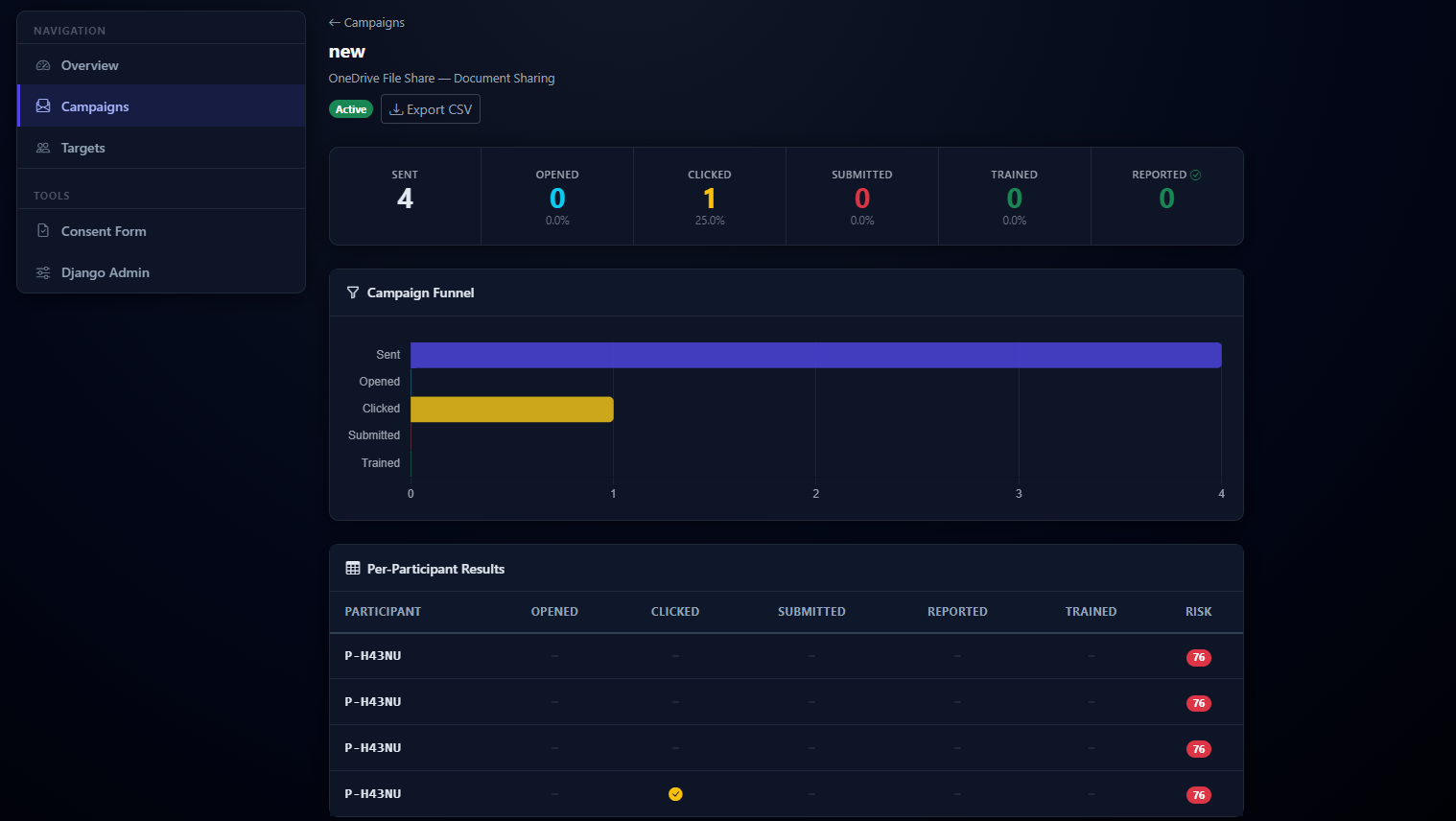
Per-campaign analytics — the full funnel from sent through trained, broken down by anonymous participant ID.
Anonymised target list — only P-XXXXX codes and departments shown, never names or emails.